The idea for this article came as I was walking to work the other day. At the most fundamental level, I marveled at the wealth of information that’s available to us in this digital age. For me personally, having access to information and data is critical – I’m a very self-motivated individual who doesn’t mind wading through the plethora of data to find what I’m looking for.
Over the past few years, I’ve taken advantage of this data availability on numerous occasions. From looking up medical information, to helping me navigate the wonderfully complex and convoluted legal system, to using the Internet as a tool to research productions before I buy. All of this has made instant availability to information a very valuable tool in my kit.
The first problem that we face is that there’s just too MUCH information available. I know that sometimes I’ll be sitting there at Google and I have to think “What is it that I’m really looking for”. This is the core starting point for research and it dictates which branch of research that we’ll take. Quite often, I’ll take a look at the preliminary search results and I’ll say “no, this isn’t what I’m looking for” and I’ll go back to how I structured my search term and I revise accordingly. Sometimes just changing the order of the phrases can make a difference in the search results.
The second problem is that once I know that I’m going along the right path, and I’m looking at the sites that were returned by the search engine, there’s still a big challenge. It’s a critical task to ascertain the legitimacy, accuracy and objectiveness of the website. I’ve said this before, but I think that it’s so important to be eternally pessimistic about the objectivity of any online source. I try to always assume that there is bias in the information presented, and if it doesn’t seem right to me, I’ll cross-reference with another site or do a brief sojourn to a separate search on this one topic.
As this article started formulating in my own mind, the general theme mutated from being just about information access to something a little bit different, and that is, what is the difference between information and knowledge.
When I came up with this question in my own mind, I thought that it would be simply a matter of looking up the dictionary definition of knowledge and from that, I can draw a comparison between it and information. It turns out that this isn’t so cut and dried.
There are numerous philosophies on what knowledge is, and what it isn’t. I had no idea that there are many debates between people that are much more philosophical than me, so I will defer on diving too much into this debate with this article.
As I think about this topic some more, I have my own definition on what knowledge is and how it relates to information.
To me, information is the data; it describes a product, a process, a law or defines and describes something. Information on its own doesn’t draw an inference as to the underlying data or otherwise make correlation between other components. My definition of knowledge is the intellectual exercise that attempts to interpret the facts that are presented.
An example I could give of this is that at a trial, the evidence presented, would be equivalent to the information. On its own, it just exists. The prosecution or the defense infers and theorizes about the evidence – this is the knowledge (or in the case the theory, I suppose) that is based on the facts presented.
If I’m on the right track about this distinction between information and knowledge, then I would contend that we truly are in the “Information Age”, that what is available to us is the raw data. The sophistication of the “Knowledge Age” will be where our technology not only presents us with the “dumb” search results but will be able to intrinsically determine what it is that we’re REALLY looking for, and attempt to deliver results in a context that’s closer to what it is that we really need.
Thursday, April 5, 2012
Tuesday, March 27, 2012
Open Source - A Wise Strategy?
The concept of open source certainly isn't new. Open source is software that the vendor has published the source code, guides and tools to allow the development community to make modifications or enhancements to the software.
Open source has been around since probably the beginning of the personal computer, so this is hardly a mind-blowing development.
There's an article on PC World today where Microsoft has adopted an open source approach to their mapping software and this has helped them to capture some of the market from Google Maps. As I read this article, it dawned on me that the concept of open source can also be a very strategic one. In a lot of respects, open source essentially adds thousands, if not tens of thousands "free developers" for the application - at least in terms of it being more desirable.
Mind you, I guess that the downside is that the company relinquishes a certain amount of control over the direction that the application takes, but I guess it's like everything else that they've carefully weighed the advantages and the disadvantages.
Open source has been around since probably the beginning of the personal computer, so this is hardly a mind-blowing development.
There's an article on PC World today where Microsoft has adopted an open source approach to their mapping software and this has helped them to capture some of the market from Google Maps. As I read this article, it dawned on me that the concept of open source can also be a very strategic one. In a lot of respects, open source essentially adds thousands, if not tens of thousands "free developers" for the application - at least in terms of it being more desirable.
Mind you, I guess that the downside is that the company relinquishes a certain amount of control over the direction that the application takes, but I guess it's like everything else that they've carefully weighed the advantages and the disadvantages.
SSOTD
Stupid spam of the day. What a silly phishing attempt. Obviously, by now, we're all intelligent enough and cautious enough to understand that financial institutions do not send us links to click on with threats that our accounts will be closed, but when you hover over the senders email address and see the address and not the sender's name, and when you hover over the link and see that the website address is nothng related to the institution...
Honestly, it's just insulting, at least put some effort into it, throw a few logos in the email, make the email address/URL even remotely similar. I understand that they're hoping that even 1 in a million fall for it, but geez, go big or go home boys.
Honestly, it's just insulting, at least put some effort into it, throw a few logos in the email, make the email address/URL even remotely similar. I understand that they're hoping that even 1 in a million fall for it, but geez, go big or go home boys.
Wednesday, March 14, 2012
Holy Cow! That's a lot of Bull - and Could Just be a lot of Udder Nonsense!
Vast departure from my usual blog entry, but I think I have a way of posting this as it's very much related to technology and humanity - or cowmanity as the case may be.
Jocko the bull has sadly passed away. Officially, he has sired 161,000 off-spring, but it's believed to be closer to 400,000. That is one heck of a commitment to his job if you ask me!
The really interesting thing is that poor Jocko only gets a bronze medal for his impressive impregnatations as there are two bulls with more off-spring. I need to find out how far behind he was.
Make no mis-steak, some other bulls will have to step up and bring their A game - or should I say their S game?
Jocko the bull has sadly passed away. Officially, he has sired 161,000 off-spring, but it's believed to be closer to 400,000. That is one heck of a commitment to his job if you ask me!
The really interesting thing is that poor Jocko only gets a bronze medal for his impressive impregnatations as there are two bulls with more off-spring. I need to find out how far behind he was.
Make no mis-steak, some other bulls will have to step up and bring their A game - or should I say their S game?
Tuesday, February 28, 2012
Finding Files or Programs – Part II
In my previous tip, I showed how easy it is to search files or programs. Certainly, when you already know the full and complete name of the file, your job is much easier.
However, what if you can only remember part of the filename? Or let’s say that you wanted to find any documents that you had worked on with the word “Budget” in them?
Before I start into the tip, there’s a little fundamental tidbit about how Windows names files. As you know, when you save a file, typically you give it a filename. Let’s say you’re creating a Microsoft Word document called “Grocery List”. What any Windows application will do is to also append a suffix to the filename to indicate what program was used to create or edit the document so that when you go to edit this document, Windows will know if it is to open up the file in Microsoft Word or Microsoft Excel. This suffix is referred to as an extension. The extension is typically a 3 or 4 character code created automatically by the application program.
To illustrate, take a look at my folder where I keep some my articles.
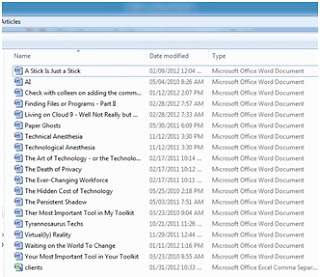
You’ll see that there is a column in my explorer called “Type”. This is based directly on the extension associated with the file. You’ll see a bunch of MS Word documents followed by one MS Excel document. In this folder, all of the Word documents have an extension of .docx and the Excel document has an extension of .xlsx
When you know the full and exact name of the file (such as “banana bread recipe.docx”) it’s much easier for you as you can just type the name of the file that you’re looking for. You’ll see that in my example here, the full name of the file starts with the name that I’ve given it (banana bread recipe) followed by the extension of the file (docx) and that there is a . so that the computer knows where the filename ends and the extension starts.
In those cases where you only know part of the filename, the operating system provides two different special symbols that are referred to as wildcards. Just like in a normal deck of playing cards, a wildcard can be used for anything but there are a couple of differences on the wildcards.
The first wildcard is the ? character and it will substitute one – and only one character. In other words, the filename pattern of j?n.docx would match either jen.docx or jon.docx. In English, the filename pattern could be interpreted as “any file where the first letter is a J, the second letter is anything else, the third letter is an N and the extension is .docx”.
The second wildcard is the * character and it is more powerful. It can replace any number of characters. Using the same example, the filename patter of j*n.docx would still match jen.docx and jon.docx but it would also match Jamison.docx.
Wildcards can be combined and repeated and can be at the beginning, in the middle or at the end of the filename (or even the extension if need be).
To close off this tip, here are some examples of wildcard patterns along with an English like description of how they would be interpreted.
However, what if you can only remember part of the filename? Or let’s say that you wanted to find any documents that you had worked on with the word “Budget” in them?
Before I start into the tip, there’s a little fundamental tidbit about how Windows names files. As you know, when you save a file, typically you give it a filename. Let’s say you’re creating a Microsoft Word document called “Grocery List”. What any Windows application will do is to also append a suffix to the filename to indicate what program was used to create or edit the document so that when you go to edit this document, Windows will know if it is to open up the file in Microsoft Word or Microsoft Excel. This suffix is referred to as an extension. The extension is typically a 3 or 4 character code created automatically by the application program.
To illustrate, take a look at my folder where I keep some my articles.
You’ll see that there is a column in my explorer called “Type”. This is based directly on the extension associated with the file. You’ll see a bunch of MS Word documents followed by one MS Excel document. In this folder, all of the Word documents have an extension of .docx and the Excel document has an extension of .xlsx
When you know the full and exact name of the file (such as “banana bread recipe.docx”) it’s much easier for you as you can just type the name of the file that you’re looking for. You’ll see that in my example here, the full name of the file starts with the name that I’ve given it (banana bread recipe) followed by the extension of the file (docx) and that there is a . so that the computer knows where the filename ends and the extension starts.
In those cases where you only know part of the filename, the operating system provides two different special symbols that are referred to as wildcards. Just like in a normal deck of playing cards, a wildcard can be used for anything but there are a couple of differences on the wildcards.
The first wildcard is the ? character and it will substitute one – and only one character. In other words, the filename pattern of j?n.docx would match either jen.docx or jon.docx. In English, the filename pattern could be interpreted as “any file where the first letter is a J, the second letter is anything else, the third letter is an N and the extension is .docx”.
The second wildcard is the * character and it is more powerful. It can replace any number of characters. Using the same example, the filename patter of j*n.docx would still match jen.docx and jon.docx but it would also match Jamison.docx.
Wildcards can be combined and repeated and can be at the beginning, in the middle or at the end of the filename (or even the extension if need be).
To close off this tip, here are some examples of wildcard patterns along with an English like description of how they would be interpreted.
Filename Pattern
|
Description
|
?arm.docx
|
Any filename that is exactly four characters wide and where the last three characters are arm and has a docx extension.
|
*budget.pdf
|
Any file with a PDF extension where there are 0, 1 or more characters of any combination suffixed with budget.
|
201? Taxes.xlsx
|
A file with an xlsx extension where the first 3 characters are 201, there is an fourth character and the suffix of the filename is taxes.
|
*family*history*.docx
|
Any MS Word document (or that has a .docx extension) where there is 0, 1 or more characters, followed by the word family, an additional 0, 1 more characters, the word history and a suffix of 0, 1 or more characters.
|
F?ar?_sales*.*
|
Any filename that begins with an F, has one character, the characters ar, followed by one more character, the word sales and any suffix of 0, 1 or more characters. In this example there is a wildcard in the extension so it would match any file types.
|
*.*
|
Every single file as this means any text in the filename and any text in the extension.
|
{kind=link}
Finding Files or Programs
One of the features that I love best about Windows is its ability to quickly type in the name of a file or a program and it will search for it. As someone who uses the keyboard much more than the mouse, this saves me a lot of time.
There are two methods that you have type in the name of a program or a file, the first is to click on the Windows Start button on the left hand corner of the task bar and type in the name of the file or program to search for as per the following screenshot:
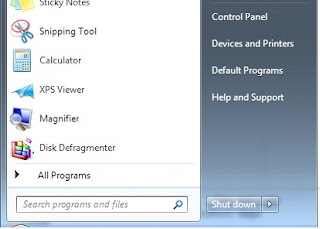
In the “Search programs and files”, you can enter in the name of the Windows program to run (i.e Word or Excel). You can also type in the name of a file that you have edited recently and it will bring that up in a selection list as well.
Another groovy trick is that this ability to search can be done without having to use the mouse to click on the Start button. To run the Search facility within Windows, while you are holding down the key with the Windows logo, press the F key to launch the Search dialog box.
There are two methods that you have type in the name of a program or a file, the first is to click on the Windows Start button on the left hand corner of the task bar and type in the name of the file or program to search for as per the following screenshot:

In the “Search programs and files”, you can enter in the name of the Windows program to run (i.e Word or Excel). You can also type in the name of a file that you have edited recently and it will bring that up in a selection list as well.
Another groovy trick is that this ability to search can be done without having to use the mouse to click on the Start button. To run the Search facility within Windows, while you are holding down the key with the Windows logo, press the F key to launch the Search dialog box.
Living on Cloud 9? Well Not Really, but Maybe One Day
 One of the biggest buzzes in technology is the proliferation of “The Cloud”. Part of the attraction of the cloud is the thought that it is an ultra-convenient place to store ones files, documents, pictures, music or what-not.
One of the biggest buzzes in technology is the proliferation of “The Cloud”. Part of the attraction of the cloud is the thought that it is an ultra-convenient place to store ones files, documents, pictures, music or what-not.In theory, there are some really interesting benefits of cloud storage and portals. As a writer, I often struggle with the dilemma of “oh gosh, my documents are at home and I had a great idea for my story!” The theory being that if I store my documents in “The Cloud” then it will remain always accessible to me and it doesn’t matter if I’m at home, or anywhere else. Presto – chango! Connect to the ‘net and Bob’s my uncle, there’s my story!
Fundamentally, this method of accessing files is only as good as one’s Internet connection. If I have my notebook on the subway and there’s no Internet connection, then there’s no access to the cloud and my documents. Even if I’m above ground on a bus for instance – unless I have a WiFi card on my network, then I’m out of luck. Now, it’s true that many new cellphones have the ability to serve as WiFi hotspots and once again – in theory – you can connect to the WiFi network on your phone, you still have to be concerned about data usage and other charges with your cell plan.
Let’s pretend for the sake of argument that we all have instant connectivity wherever we are. Is everything good? Is “The Cloud” a viable alternative?
The answer is not so simply…it depends…there’s a slew of other issues to consider when storing documents online.
Alright, so how many of you have Facebook – hands up! Now, everyone who has read the entire terms of service of Facebook, you can put your hand down. So now that everyone still has your hand up – if you store pictures on your Facebook page, or have any personal content, are you aware that when you signed up for Facebook, you have granted them the right to use any of your content, for any purposes, royalty free? I’m not picking on Facebook, carefully read the TOS for many of these free “services” and you’ll see that they may be free but they don’t come without a price. A similar example is DeviantArt – where I actually store my artwork. I checked tonight and it’s TOS (terms of service) also grants them royalty free use of any of my artwork without requiring my permission. Fortunately, my art pretty much sucks so I don’t have to worry about it being turned into millions of coffee mugs or such.
Legalities aside, think for a moment on if you’re having a fantastic time using some online portal to store your documents – like I sometimes do with Google Documents. Access to your documents are only as good as the service is up and running. A perfect example is the recent MegaUpload issue. This was a website that was being used for people to be able to store their documents, music and movies. The problem was that these files were then shared and legal action was initiated against the site for copyright violation. The net of copyright infringement was cast far too wide and it caught some innocent fish that did not share a thing – but just used MegaUpload as online storage.
It’s a scary digital world out there and sometimes I find that I will use a technology just for convenience sake without really looking at the consequences and to think of the possible impact.
Like so many areas of technology, it tantalizes us and hooks us with the promise of ease and convenience. Kind of like the wizard in Oz, sometimes it’s necessary to pull back the curtain to see what is really there.
Alright, so how many of you have Facebook – hands up! Now, everyone who has read the entire terms of service of Facebook, you can put your hand down. So now that everyone still has your hand up – if you store pictures on your Facebook page, or have any personal content, are you aware that when you signed up for Facebook, you have granted them the right to use any of your content, for any purposes, royalty free? I’m not picking on Facebook, carefully read the TOS for many of these free “services” and you’ll see that they may be free but they don’t come without a price. A similar example is DeviantArt – where I actually store my artwork. I checked tonight and it’s TOS (terms of service) also grants them royalty free use of any of my artwork without requiring my permission. Fortunately, my art pretty much sucks so I don’t have to worry about it being turned into millions of coffee mugs or such.
Legalities aside, think for a moment on if you’re having a fantastic time using some online portal to store your documents – like I sometimes do with Google Documents. Access to your documents are only as good as the service is up and running. A perfect example is the recent MegaUpload issue. This was a website that was being used for people to be able to store their documents, music and movies. The problem was that these files were then shared and legal action was initiated against the site for copyright violation. The net of copyright infringement was cast far too wide and it caught some innocent fish that did not share a thing – but just used MegaUpload as online storage.
It’s a scary digital world out there and sometimes I find that I will use a technology just for convenience sake without really looking at the consequences and to think of the possible impact.
Like so many areas of technology, it tantalizes us and hooks us with the promise of ease and convenience. Kind of like the wizard in Oz, sometimes it’s necessary to pull back the curtain to see what is really there.
Subscribe to:
Comments (Atom)